Is economics getting better? Yes. It is.
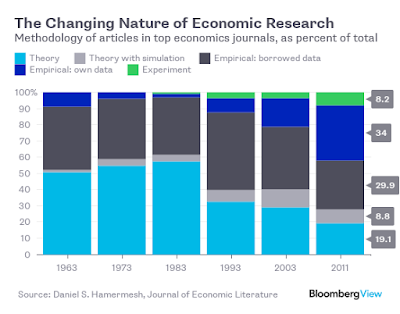
I attended two great conferences last week. The first one was an econ conference I co-organized with my friends and colleagues Dr Dejan Kovac and Dr Boris Podobnik , which featured three world-class economists from Princeton and MIT: professors Josh Angrist , Alan Krueger , and Henry Farber . The second was the annual American Political Science Association conference in San Francisco. I am full of good impressions from both conferences, but instead of talking about my experiences I will devote this post to one thing in particular that caught my attention over the past week. A common denominator, so to speak. Listening to participants present their excellent research in a wide range of fields, from economics to network theory (in the first conference), from political economy to international relations (in the second), I noticed an exciting trend of increasing usage of scientific methods in the social sciences. Methods like randomized control trials or natural experiments are slo